Why I built Passages
I wrote recently about why I can’t read on computer screens and the capture–organize–read workflow I developed to deal with it. Passages is the tool I built to make that workflow real.
I looked at what was out there, from read-later to send-to-Kindle services, and none of them did exactly what I wanted. They were either too focused on reading inside the app itself, or they treated the e-reader as an afterthought. I wanted something that treated the e-reader as the destination from the start, and that gave me control over how my reading was organized and formatted.
Going back to the Capturing → Organizing → Reading workflow I described in the previous post, Passages implements it clearly as its core foundations.
Capturing
Capturing an article takes a single click. There is a browser extension for Chrome and Firefox, and a bookmarklet for anything else. You click, the article is saved, and you move on. That’s it. The whole point is to not interrupt whatever you were doing.
Organizing
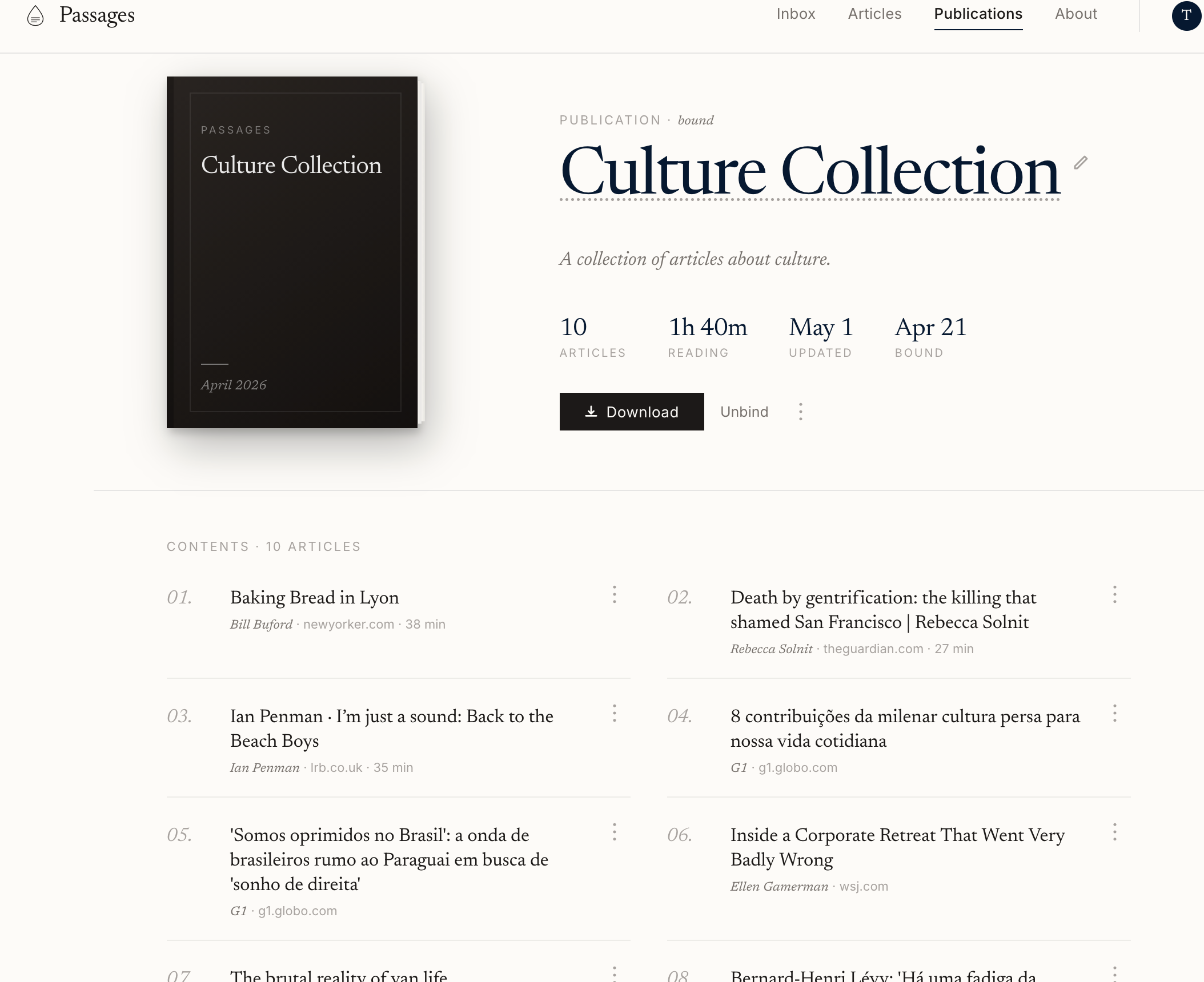
Captured articles land in an inbox, ready to be triaged. From there, you can group them into what Passages calls Publications, which are collections of articles organized by any criteria you choose: date, author, topic, or whatever makes sense to you. Think of them as custom magazines you assemble yourself.
Once a publication feels ready, you “bind” it, which means Passages transforms it into an ebook that can be downloaded or sent wirelessly to your Kindle or Kobo.
Reading
A lot of effort went into the content extraction and rendering. The parsing algorithm is tuned for e-reader screens — it produces clean prose with simpler formatting, fewer images, and no interactive elements like videos or embedded widgets. The rendering engine is built specifically for assembling collections of articles into different ebook formats, and the result is a comfortable, natural reading experience.

Where it is now
It’s been a lot of fun building Passages so far. I built it to scratch my own itch and have learned a lot about ebook formatting and content parsing along the way. More importantly, I’ve managed to increase my reading time and shrink my read-later backlog — which was the whole point.
The current version has everything I wanted. I have plenty of ideas for integrations and more advanced features, but I’m holding off to learn what users actually want first.
This is a passion project, and I put a small monthly price on it to test whether it can sustain itself. If you are interested in trying it out, sign up and send me a message — I’m happy to grant you an unlimited free pass.